Advertisement
Audio work used to feel like something only audio engineers or musicians could touch. That’s changed. Librosa, a Python library for music and audio analysis, has made it possible for developers and researchers to work with audio files easily. Whether you're training a model to recognize speech or exploring acoustic features in a dataset, Librosa gives you practical tools without requiring a deep background in signal processing. It handles file loading, visualization, feature extraction, and preprocessing with functions that are clear, useful, and work well with other Python libraries.
Start by loading your audio file using librosa.load(). This function gives you a NumPy array representing the audio time series and the sample rate. By default, it loads audio in mono at 22,050 Hz, though you can change that. Standardizing these settings helps with machine learning pipelines or when merging different datasets.
You can plot the waveform using librosa.display.waveshow() and Matplotlib. This gives a quick look at volume changes, silences, or sudden peaks. If your clip includes long, quiet parts or sharp sounds, these become immediately visible.
To go deeper, convert the waveform into a spectrogram using librosa.stft(). This breaks the audio into small time slices and shows how frequencies vary across time. Display it with librosa.display.specshow() to reveal pattern,ssuch ase voice intonations, rhythms, or frequency range,s that persist or shift. This is especially helpful in speech tasks or identifying audio signatures.
Working with raw audio isn’t ideal for data tasks. You need meaningful features that summarize the clip. Librosa provides ready-made functions to extract useful characteristics.
MFCCs (mel-frequency cepstral coefficients) are one of the most popular features. They're used heavily in speech and music classification. With librosa.feature.mfcc(), you get a matrix of coefficients over time that represent the audio's frequency content. You can average them or keep the full-time series, depending on your task.
Chroma features, from librosa.feature.chroma_stft(), map the audio onto 12 pitch classes. These are useful in tasks involving music and audio analysis, like genre detection or chord recognition. If you're working with melodies or harmonic content, chroma features reveal tonal shifts and key changes.
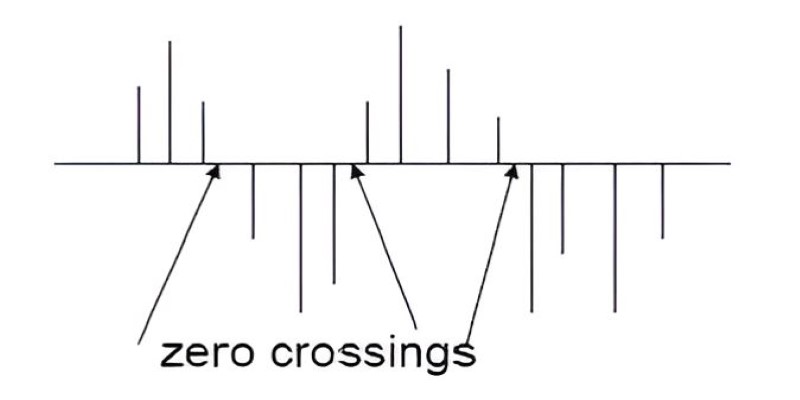
For simpler metrics, the zero-crossing rate (ZCR) measures how often the signal crosses zero. It’s useful for distinguishing noisy or unvoiced sounds. RMS energy reflects the average volume over time. Both are helpful in detecting silence or segmenting speech.
Librosa also supports tempo and beat tracking. With librosa.beat.beat_track(), you can estimate beats per minute and locate beat positions. This is useful in musical analysis or aligning audio to rhythm-based tasks.
Often, before analysis or modeling, you need to clean or adjust the audio. Librosa supports common preprocessing tasks, such as trimming silence, adjusting speed, and shifting pitch.
Silence at the beginning or end of a clip can confuse models. Use librosa.effects.trim() to cut it. The function detects sections of low energy and removes them automatically.
If your files come at different sample rates, standardize them with librosa.resample(). This avoids mismatches later, especially in batch processing. Uniform sampling rates also reduce variability in feature extraction.
Pitch shifting is handled by librosa.effects.pitch_shift(). This changes the perceived pitch while keeping the timing the same. It's useful for data augmentation or musical transformations. For time stretching—slowing or speeding up the audio without changing the pitch—use librosa.effects.time_stretch(). Both are good ways to enrich your training data or simulate different recording conditions.
Librosa doesn't do denoising directly, but you can combine it with SciPy or other tools. For example, use the waveform or spectrogram to locate noisy sections, then apply external filters.
Librosa is made to fit naturally into machine learning workflows. Its functions return NumPy arrays, which connect smoothly to Scikit-learn, TensorFlow, and PyTorch.
After extracting MFCCs or other features, average them across time to produce a fixed-length vector. These vectors can go straight into a classifier. If you're working with time-series models, such as RNNs, use the full feature sequence instead.
Librosa works well with pandas. You can create a data frame where each row holds the features for one audio file, and columns represent MFCCs, chroma, ZCR, or other statistics. This format is ideal for debugging or visual inspection.
The library supports music and audio analysis particularly well. Tools like harmonic-percussive source separation (librosa.effects.hpss()), beat tracking, and chroma extraction are tailored for musical tasks. But they also help in broader settings—environmental sound classification, speaker identification, or audio tagging.
You can build automated pipelines using Librosa. For example, load, trim, resample, extract MFCCs, and scale the features. Wrap this into a function and apply it to hundreds or thousands of files. The consistency and simplicity of Librosa functions help keep the code clean and fast.
Librosa is also helpful in audio segmentation tasks. You can combine ZCR, RMS, and spectral features to locate changes in the sound, such as the start of a spoken phrase or a switch in background noise.
For neural networks, normalization is important. Librosa doesn’t provide scaling out of the box, but it integrates well with Scikit-learn’s StandardScaler or MinMaxScaler. Once features are extracted, use these tools to normalize input for training.
If you’re working with convolutional networks, spectrograms or chromagrams can be used as images. Save them using Matplotlib and feed them into image-based pipelines. This bridges audio analysis and computer vision.
Librosa makes working with audio simpler, faster, and less technical. You don’t need to write complex math to understand what's going on in a sound file. From loading to transforming, from feature extraction to integration with machine learning, Librosa covers the entire process. Its clean API, NumPy compatibility, and focus on real use cases make it ideal for anyone handling audio in Python. Whether you’re doing speech analysis, building a classifier, or working on a creative project involving sound, Librosa helps you focus on ideas, not code. Once you're familiar with its functions, you’ll find yourself moving smoothly through every stage of your audio workflow.
Advertisement

Explore the real pros and cons of using ChatGPT for creative writing. Learn how this AI writing assistant helps generate ideas, draft content, and more—while also understanding its creative limits

IBM AI agents boost efficiency and customer service by automating tasks and delivering fast, accurate support.

Google debuts new tools and an agent protocol to simplify the creation and management of AI-powered agents.

How Phi-2 is changing the landscape of language models with compact brilliance, offering high performance without large-scale infrastructure or excessive parameter counts

Hugging Face enters the world of open-source robotics by acquiring Pollen Robotics. This move brings AI-powered physical machines like Reachy into its developer-driven platform

How to use Librosa for handling audio files with practical steps in loading, visualizing, and extracting features from audio data. Ideal for speech and music and audio analysis projects using Python

Discover OpenAI's key features, benefits, applications, and use cases for businesses to boost productivity and innovation.

Learn how AWS Strands enables smart logistics, automation, and much more through AI agents.

Is premium AR worth the price? Discover how Xreal Air 2 Ultra offers a solid and budget-friendly AR experience without the Apple Vision Pro’s cost

Curious about Vicuna vs Alpaca? This guide compares two open-source LLMs to help you choose the better fit for chat applications, instruction tasks, and real-world use

Why INDEX MATCH is often a better choice than VLOOKUP in Excel. Learn the top 5 reasons to use INDEX MATCH for more flexible, efficient, and reliable data lookups

How indentation in Python works through simple code examples. This guide explains the structure, spacing, and Python indentation rules every beginner should know